Here’s a look at the Wayback Machine and what makes it special.
Internet Archive Introduction
Created by Brewster Kahle and Bruce Gilliat, the Internet Archive is a non-profit organization with a stated mission of “universal access to all knowledge.” From the beginning, the organization has provided free public access to digitized materials, such as web pages, books, audio recordings, including live concerts, videos, images, and software programs. To date, everything collected by the Internet Archive takes up more than 70 Petabytes of server space, including two copies of everything. The organization is funded through donations, grants, and fees from book digitization services. For privacy, the Internet Archive doesn’t keep track of the IP addresses of its readers and uses the HTTPS (secure) protocol throughout.
The Wayback Machine
Just one part of the Internet Archive, the Wayback Machine, was designed to capture website content that’s changed or removed. Since launching, it has become one of the most popular and recognized places on the web. Kahle and Gilliat named the site after the fictional time-traveling device in the 1960s animated series, The Rocky and Bullwinkle Show. Though Internet Archive didn’t launch the site to the public until October 2001, the Wayback Machine began archiving cached web pages beginning in May 1996. Until 2001, digital tapes stored information that was only accessible to select scientists and researchers. When everything went live to the public five years later (as was long-planned), it had already contained over 10 billion archived pages.
Storage and Collections
Today, the site keeps historical web data on a cluster of Linux nodes. The Wayback Machine downloads all publicly accessible information and data files on web pages through its crawl mechanism. However, not everything posted on a website is included here since some content is restricted or stored in databases, which aren’t accessible. Because of this, some websites are better crawled than others, depending on how developers created a site at a time. You’ll also notice the newer the archive, the more content available for any given site. A new tool the Internet Archive introduced in 2005 is one of the reasons newer data is more complete. Archive-It.org helps to overcome inconsistencies in partially cached websites by allowing institutions and content creators to harvest and preserve collections of digital content.
About Crawling
Web crawlers, sometimes called spider or spiderbot, are as old as the internet itself. These crawlers are internet bots that continuously browse the web for indexing purposes, making them an important component of any modern search engine. The crawlers used for the Wayback Machine to create digital snapshots of websites come from various sources, which have changed over time. As you’ll quickly notice, the frequency of snapshot captures varies greatly by the website. Typically, the larger (and perhaps more popular) a website, the more crawling that occurs. Plus, a lot depends on how often a website has page changes. Even the smallest websites are eventually crawled unless there’s a reason they are not. For example, password-protected sites aren’t crawled, and neither are websites whose site owners have requested they not be included.
Using the Wayback Machine
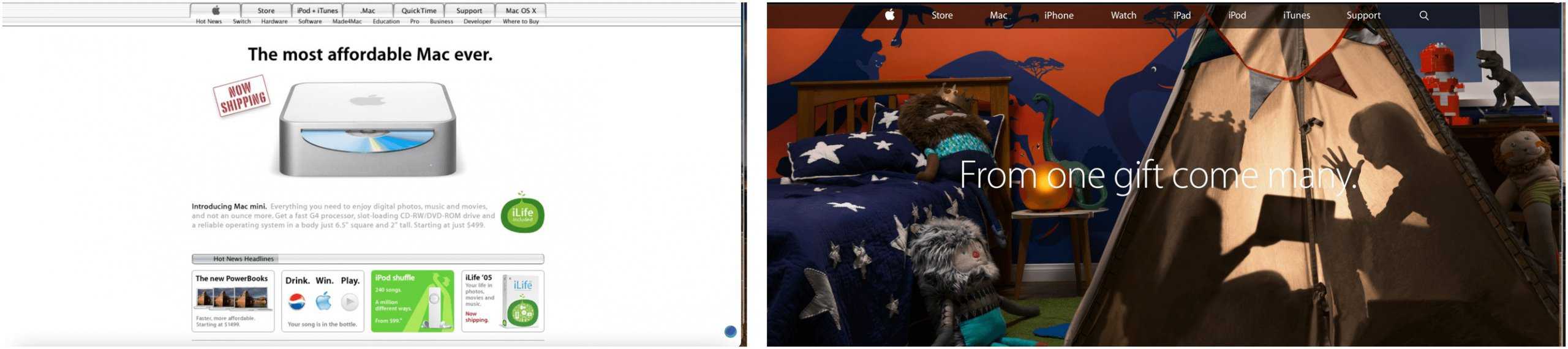
The Wayback Machine website is easy for anyone to use. To find historical snapshots of a website, type its name into the site’s search engine. On the search results page, hyperlinks denote dates and times a site was archived. Click on the link to see the site “back in time.” In the following examples, you can see the front page of the Apple website recorded in February 2005 and November 2014, and the CNN homepage from a date in March 2004 and September 2010. Note: These crawls also include links to other pages as recorded on the given dates, not just the home pages.
Advanced Tools
Created for researchers and the public alike, the Wayback Machine has a few built-in tools that casual users might miss. For example, by design, search result pages are easy to reference. As explained, “If you find an archived page that you would like to reference on your Web page or in an article, you can copy the URL. You can even use fuzzy URL matching and date specification… but that’s a bit more advanced.” The Wayback Machine also allows site owners to use a “Save Page Now” feature to save a specific page. And yet, it’s not perfect. Currently, the feature doesn’t add the site URL to any future crawls. Additionally, the request doesn’t save more than one page. However, it’s a good first step to archive your website’s homepage for the historical record.
You don’t have to visit the Wayback Machine every time to do a new search. Instead, you can find content by typing in the address in your web browser toolbar. Use this format for all searches: https://web.archive.org//www.yoursite.com/. For example, use https://web.archive.org//www.groovypost.com/ to find archived pages for the GroovyPost!
Mobile and Developer Tools
Finally, the Wayback Machine isn’t just located through the web. You can find a Wayback Machine app for iOS and Android. There are also extensions for Chrome, Safari, and Firefox. Developers will also want to check out the Internet Archive Wayback Machine APIs. These make it easier for developers to retrieve information about Wayback capture data. The Internet Archive Wayback Machine supports several different APIs. By doing so, it makes it easier for developers to retrieve information about Wayback capture data. Going “back in time” for your favorite websites is the No. 1 reason to visit the Wayback Machine. It’s also a great tool for anyone researching website history for school projects or business use. Whatever you do, visit the Wayback Machine and see what you can discover in a few simple steps. For more information on the Internet Archive’s Archive-It subscription service, visit the official website and start contributing today! Comment Name * Email *
Δ Save my name and email and send me emails as new comments are made to this post.




![]()
